
안녕하세요.
오랜만에 코딩일기로 돌아온 세무민입니다.
사실 요즘 회사 일에 치여서 이걸 포스팅 할까 고민하다가
그래도 Spring Batch에 대해 조금이나마 작성하면 좋을 것 같아서 포스팅으로 남깁니다.
1. Spring Batch 개발을 하게 된 목적
목적은 서비스에 산재되어 있는 Scheduler를 하나의 서비스로 모으는데 목적을 가졌었어요
그러면서 조금이나마 Spring Batch와 Quartz에 대해 개인적으로 프로젝트를 해보게 되었답니다.
2. Spring Batch VS Spring Scheduler
- Batch란 일괄처리를 말하며 사용자의 상호작용 없이 여러개의 작업을 미리 정해진 순서에 따라 중단 없이 처리
- Scheduler는 특정한 시간에 등록한 작업을 자동으로 실행시키는 것을 의미
- Scheduler의 경우 Spring에 기본 기능으로 추가 의존성이 필요 없다는 점과 간편하다는 장점이 있으나 단일 Thread를 사용
- Spring Scheduler의 경우 사용 옵션이 존재
- fixedDelay : 스케줄러 끝나는 시간 기준 1초 간격 진행
- fixedRate : 스케줄러 시작하는 시간 기준 1초 간격 진행
- Spring Scheduler의 경우 사용 옵션이 존재
- 즉, Scheduler와 Batch는 다른것이 아니라 역할이 다르다는 점만 알아두시면 됩니다.
- Scheduler는 특정 시간에 작업을 실행, Batch는 실행해야 하는 작업들을 순서대로 처리
3. Spring Batch 특징
- 대용량 데이터 처리 용이
- 자동화 기능
- 데이터 충돌/중단 없이 처리 가능
- 지정한 시간 안에 처리를 완료하거나 동시에 실행되는 다른 프로그램을 방지하지 않음(동시성 제어)
- 로깅, 알림을 통한 추적이 가능
4. Spring Batch 상세 설명
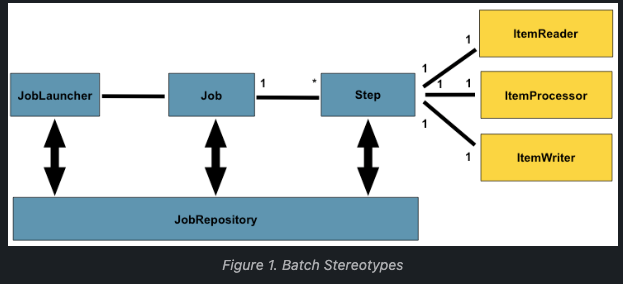
Spring에서 제공해주는 Spring Batch의 구조입니다.
실질적으로 JobLauncher > Job > Step > Tasklet/Chunk 처리 구조라고 보면 될 것 같습니다.
Spring Batch와 관련된 용어에 대해서는 아래와 같습니다.
Job
- 배치 처리 과정의 하나의 단위
- 배치 처리 과정의 전체 계층에 가장 상단에 위치
JobInstance
- Job의 실행 단위
- 2/23일, 2/24일 실행 시 각각의 JobInstance 생성
JobParameters
- JobInstance 구분 값
- String, Double, Long, Date 4가지 형식을 지원
JobExecution
- JobInstance에 대한 실행 시도 객체
- 실패하여 재실행 시킨 경우 동일한 JobInstance이나 2번 실행에 대한 JobExecution은 개별로 생성
- JobInstanced 실행에 대한 상태, 시작시간, 종료시간, 생성시간 등의 정보로 생성
Step
- Job의 배치 처리를 정의하고 순차적인 단계를 캡슐화
- Job은 최소한 1개 이상의 Step을 가져야 하며 Job의 실제 일괄처리를 제어하는 모든 정보 포함
- 방식은 크게 TaskLet과 Chunk로 나눠진다.
StepExecution
- Step 실행 시도에 대한 객체
- 이전 단계의 Step이 실패하면 StepExecution은 미생성
- 실제 시작이 될 때만 생성
- StepExecution은 JobExecution에 저장되는 정보 외에 read 수, write 수, commit 수, skip 수 등의 정보들이 저장
ExecutionContext
- Job에서 데이터를 공유 할 수 있는 데이터 저장소
- Spring Batch에서 제공하는 ExecutionContext는 JobExecutionContext, StepExecutionContext 2가지 종류이며 지정 범위가 다름
- JobExecutionContext의 경우 Commit 시점에 저장되는 반면 StepExecutionContext는 실행 사이에 저장
- ExecutionContext를 통해 Step간 Data 공유가 가능하며 Job 실패시 ExecutionContext를 통한 마지막 실행 값을 재구성 가능
JobRepository
- 위의 모든 배치 처리 정보를 담고있는 매커니즘
- Job이 실행되게 되면 JobRepository에 JobExecution과 StepExecution을 생성하게 되며 JobRepository에서 Execution 정보들을 저장하고 조회할 때 사용
JobLauncher
- JobLauncher는 Job과 JobParameters를 사용하여 Job을 실행하는 객체
ItemReader
- Step에서 Item을 읽어오는 인터페이스
- ItemReader에 대한 다양한 인터페이스가 존재하며 다양한 방법으로 Item을 읽기 가능
ItemWriter
- 처리된 Data를 Writer할 때 사용합니다.
- 처리 결과물에 따라 Insert, Update, Queue의 Send 등 가능
- 기본적으로 Item을 Chunk로 묶어 처리
ItemProcessor
- Reader에서 읽어온 Item을 데이터 처리하는 역할
- Processor는 배치를 처리하는데 필수 요소는 아니며 Reader, Writer, Processor 처리를 분리하여 각각의 역할을 명확하게 구분
5. TaskLet/Chunk
배치를 처리할 수 있는 방법은 크게 2가지로 TaskLet과 Chunk가 있습니다.
TaskLet
- 각 단계는 하나의 정의된 작업만 수행해야 함
- Step이 중지될 때까지 execute 매서드가 계속 반복해서 수행하고 수행할 때마다 독립적인 트랜잭션을 사용
- 초기화, 저장, 실행, 알림 전송과 같은 Job에 사용
- tasklet 클래스 재사용이 가능할 경우 사용
- Tasklet을 사용한 Task 기반 처리
- 배치 처리 과정이 비교적 쉬운 경우 쉽게 사용
- 대량 처리를 하는 경우 더 복잡
- 하나의 큰 덩어리를 여러 덩어리로 나누어 처리하기 부적합
- Tasklet을 사용한 Task 기반 처리
Chunk
- 한번에 하나의 Row를 읽어 Chunk를 만들고 Chunk단위로 트랜잭션을 분리
- 한번에 모든 행을 읽고 사용하지만 한번에 고정된 청크를 읽고 처리
- Chunk 단위로 트랜잭션을 수행하기 때문에 실패하더라도 Chunk만큼 롤백되며 커밋된 트랜잭션 범위까지는 반영
- Chunk를 사용한 chunk(덩어리) 기반 처리
- ItemReader, ItemProcessor, ItemWriter의 관계 이해 필요
- 대량 처리를 하는 경우 Tasklet 보다 비교적 쉽게 구현
- 예를 들면 10,000개의 데이터 중 1,000개씩 10개의 덩어리로 수행
- Chunk를 사용한 chunk(덩어리) 기반 처리
6. Spring Batch MetaTable
Spring Batch 프로젝트를 만들기 위해서는 기본적으로 MetaTable을 만들어야 합니다.
- 메타테이블을 이용하여 Job과 Step의 로깅을 할 수 있음
- 설정에 따라 InMemory DB를 이용할 수도 있음

- 총 6개의 메타 테이블을 생성해주면 되며 추후 커스텀을 할 경우라면 6개의 테이블과 3개의 시퀀스를 만들어 주면 됩니다.
- 관련된 내용은 추후 다른 포스팅에서 다루도록 하겠습니다.
7. 기타
GitHub - sg-moomin/springbatchapi
Contribute to sg-moomin/springbatchapi development by creating an account on GitHub.
github.com
포스팅과 관련된 코드를 볼 수 있습니다.
이번 포스팅에서는 Spring Batch 이론에 대해 간단하게 설명하였습니다.
다음 포스팅에서는 실제 Spring Batch 개발하는 포스팅으로 돌아오겠습니다.
'Programing > Java & Spring' 카테고리의 다른 글
| 세무민의 코딩일기 : Spring Batch JobParameterVaildator (0) | 2023.11.28 |
|---|---|
| 세무민의 코딩일기 : Spring Batch API 만들기 2탄(Job, Step, TaskLet를 직접 사용해보자) (0) | 2023.10.30 |
| [Spring] Scheduling LockProvider 사용 목적과 사용 시 고려할 사항 정리 (0) | 2023.03.21 |
| Java 예외(Exception) 처리 이론 정리 (0) | 2022.10.19 |
| 세무민의 코딩일기 : 포트폴리오 화면에 블로그 기능 추가하기 2탄 [포트폴리오 사이트 제작하기 4탄] (0) | 2022.02.13 |