인턴 중 파싱을 돌리면서
남은 시간을 뭐하면서 보낼지 고민하다가
전에 했던 시각화를 기록으로 남기는걸 선택했다.
우선 SVG를 만드는 것을 목표로 진행 할 예정!
추가적으로 양이 너무 많으면 포스팅을 나눠서 진행할 예정입니다.
이번 포스팅에서 주로 다뤄질 데이터는 서울시 소방장비현황에 대한 자료입니다.
자료의 출처가 기억은 안나지만 다른 자료로 유사하게 작업이 가능합니다!
예시 URL : opengov.seoul.go.kr/
정보소통광장
서울시 정보공개포털. 결재문서 원문공개, 사전정보공표, 정보공개청구, 정책연구자료, 백서 제공
opengov.seoul.go.kr
서울시에서 제공하는 정보소통광장에서
서울시에 관련된 데이터를 수집할 수 있습니다.
대신 가공은 여러분들의 목!
import pandas as pd
import numpy as np
from pandas import Series, DataFrame
서울특별시1 = pd.read_excel("서울특별시_2016_소방장비현황.xlsx")기본적으로 pandas와 numpy를 임폴트해주고
서울특별시 소방장비에 대한 엑셀까지 불러옵니다.
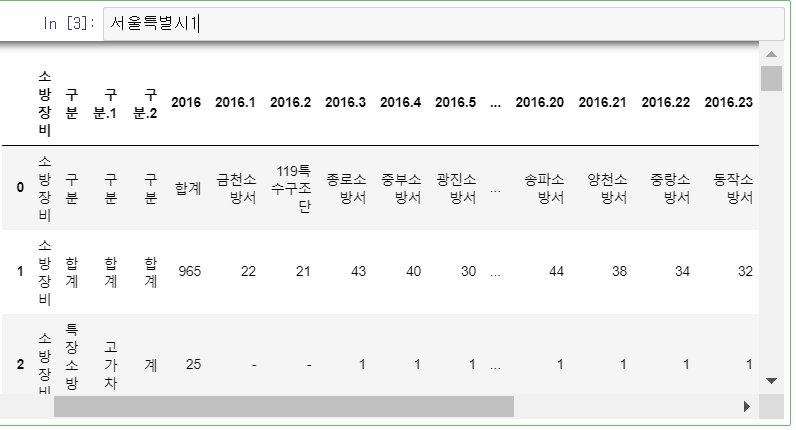
데이터를 확인해보면....
정리가 안된 모습을 확인할 수 있습니다.
그러면 가장 우선적으로 해야하는 작업은?
DataFrame의 컬럼명과 필요없는 값들을 정리하는 것!
모든 데이터를 가공할 때 가장 중요한 건 필요없는 값을 없애고 keyWord를 살려서 분석하는게 최고!
서울특별시1 = 서울특별시1.drop([1,2,3,4,5,6,7,8,9,10,
11,12,13,14,15,16,18,19,20,
21,22,24,25,26,27,28,30,31,
32,33,34,35,36,37,39,40,
41,42,44,45,46,49,50,51,52,53,54,
56,57,58,59,60])
서울특별시_1 = np.transpose(서울특별시1)
서울특별시_1 = 서울특별시_1.drop(['소방장비','구분','구분.2'])
서울특별시_1 = 서울특별시_1.replace("-", 0)
위의 코드처럼 제 입맛에 알맞게 수정을 해줍니다.
필요없는 컬럼값들을 날리거나
행열을 변환해주고 필요없는 값은 날리고
null 또는 특수문자는 0으로 처리한다던지 등등
테스트 겸 데이터를 1차 가공을 진행합니다.
이렇게 하는 이유는 사실상 공공데이터나 데이터를 처음에 받았을 경우
기본적으로 완성된 데이터를 받는 다는건 쉽지 않고 대부분 정형화가 안된 데이터나 의미없는 데이터들이 많은데
이런 데이터들을 어떻게 가공하는지가 중요합니다!
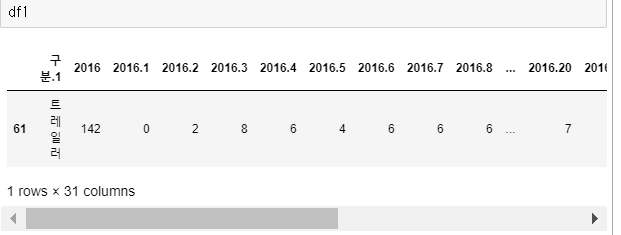
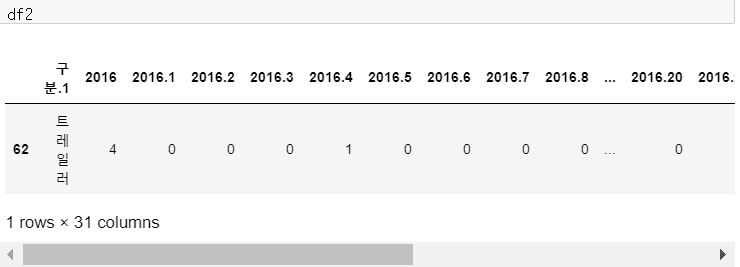
1차 가공을 완료하면 대략 위의 테이블처럼 트레일러에 대한 값을 사용할 준비가 되었습니다.
merge1 = pd.merge(df1, df2, how='outer')
merge1 = np.transpose(merge1)다음으로는 2개의 DataFrame을 병합합니다.
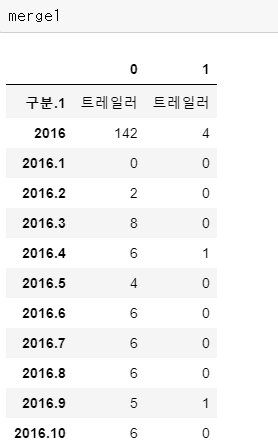
병합을 해서 2개를 1개로 합쳐줍니다.
여기서 행과 열의 인덱스를 보면 의미 없는 값들로 나열된 모습을 볼 수 있습니다.
이렇게 되면 어떤 데이터인지 식별이 불가능합니다.
merge2 = merge1[0] + merge1[1]
merge2 = DataFrame(merge2)
merge2 = merge2.rename(columns={0:'기타차'})
merge2 = np.transpose(merge2)
merge2.loc[1] = 서울특별시_1[0]위처럼 코딩을 합니다.
먼저 merge2라는 변수를 만들어주고 DataFrame으로 변환해줍니다.
그리고 컬럼의 0번째를 기타차로 변경해줍니다.
죽 위에서 0, 1이라고 나와있는 컬럼명을 변경해줍니다.
그리고 행과 열을 Change!
마지막으로 서울특별시_1이라는 변수의 값을 그대로 입혀줍니다.

이러한 결과를 확인할 수 있습니다.
위에서 말했던 것처럼 결국에 1차 가공을 어떻게 하는지에 따라서 데이터의 사용도가 다를것으로 생각됩니다.
결국 의미없는 값을 없애고 필요한 값들만 이용하는 것이 가장 베스트!
서울특별시_1 = 서울특별시_1.rename(columns={0:'구분',17:'펌프차',23:'화학차',29:'구급차',
38:'조배연차',43:'지휘자',47:'화재조사차',48:'순찰차',
55:'행정차',61:'이륜차',62:'트레일러'})
서울특별시_1 = 서울특별시_1.set_index('구분')
서울특별시_1 = 서울특별시_1.drop(['구분'])
위에서 사용했던 기본 데이터를 이제 다시 제가 원하는 DataFrame으로 변환시켜보겠습니다!
1차 가공처럼 필요있는 데이터들만 남기기 위해서
컬럼명을 변환해주거나 인덱스를 지정해주는 등 작업들을 진행합니다.
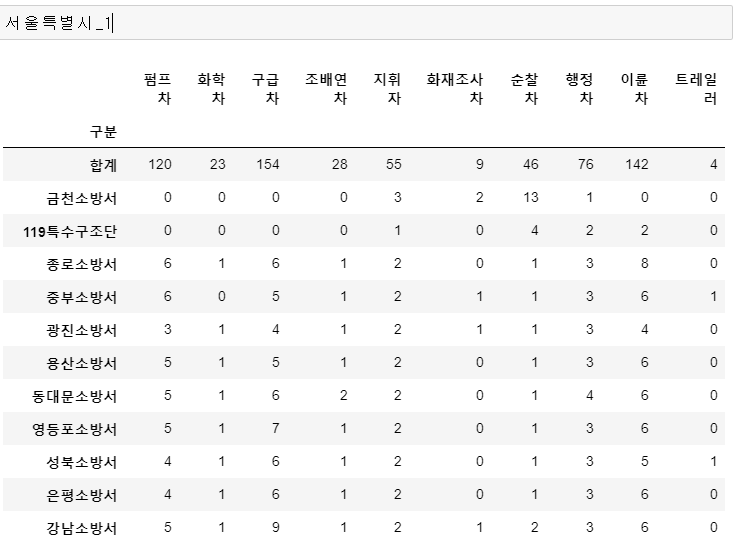
깔끔해진 DataFrame을 확인할 수 있습니다.
시각화를 하거나 SVG로 변환하기 위해서는 데이터를 잘 가공하는 것이 필수!
서울특별시_M = pd.merge(서울특별시_1, merge2, left_index=True, right_index=True, how='outer')
서울특별시_M = 서울특별시_M.drop(columns={'이륜차','트레일러'})
서울특별시_M = 서울특별시_M.reset_index()위에서 만들었던 merge2와 서울특별시_1 변수를 outer조인을 진행해줍니다.
outer조인은 말 그대로 모든값을 합친다고 생각하면 쉽습니다.
그 후에 필요없는 값들을 날려버리고 인덱스까지 초기화 하면 끝!
reset_index를 하면 인덱스가 초기화됩니다!

정리된 데이터들의 모습 ㅎㅎ
참 깔끔하군요 ㅎㅎ
기존 데이터는 컬럼명이랑 모든 값들이 불규칙했으나
지금은 규칙적인 모습을 확인할 수 있습니다.
이렇게 만든 데이터를 마지막 2차 가공을 진행합니다.
서울특별시_M = 서울특별시_M.rename(columns={'구분':'소방장비','조배연차':'배연차'})
서울특별시_M["합계"] = 0
서울특별시_M['합계'] = 서울특별시_M['펌프차'] + 서울특별시_M['화학차'] + 서울특별시_M['구급차'] + 서울특별시_M['배연차'] + 서울특별시_M['지휘자'] + 서울특별시_M['화재조사차'] + 서울특별시_M['순찰차'] + 서울특별시_M['행정차'] + 서울특별시_M['기타차']
서울특별시_M = 서울특별시_M.set_index('소방장비')
서울특별시_M = np.transpose(서울특별시_M)
서울특별시_M = 서울특별시_M.reset_index()
서울특별시_M = 서울특별시_M.drop([0,1,2,3,4,5,6,7,8])
서울특별시_M = np.transpose(서울특별시_M)
서울특별시_M = 서울특별시_M.reset_index()
서울특별시_M = 서울특별시_M.drop([0,1])
서울특별시_M = 서울특별시_M.rename(columns={9:'합계'})
서울특별시_M = 서울특별시_M.set_index('소방장비')
서울특별시_M.to_excel('소방장비현황_서울특별시.xlsx', encoding="ms949")컬럼명을 재 지정해주는 작업을 시작으로
합계가 일치하지 않아서 새로 초기화 작업을 진행하고
전에 reset했던 인덱스도 재 지정 등 필요없는 값들을 없애고 필요한 값들로 DataFrame을 새로 만든 후
xlsx파일로 저장해주면 끝!
여기서 csv로 변환해도 무관합니다!
제가 포스팅에서 표현하는 1차 가공과 2차 가공에 대해서 간략하게 설명드리면
1차 가공은 완전 불규칙한 데이터이거나 쓸수 없는 상태의 데이터를 초기작업을 하는 것!
2차 가공은 DataFrame에 필요한 값들만 남았으나 컬럼명이 일치하지 않거나 의미없는 값들이 존재하는지 여부 확인!
이렇게 2개의 단계로 나눠서 진행합니다.
한번에 모든걸 다 해도 좋지만
저는 데이터 분석에서는 눈으로 보면서 하는걸 중요하게 생각하기 때문입니다.
내용이 생각보다 길어서 남은 내용은 다음 포스팅에서 잘 정리해보도록 하겠습니다!
'Programing > Python' 카테고리의 다른 글
| 파이썬 웹 개발을 위한 기초 공부하기 3탄 - django 기본 틀 잡기 및 DB 설계 초본 제작 (0) | 2021.12.08 |
|---|---|
| 파이썬 웹 개발을 위한 기초 공부하기 2탄 - Flask 기본 툴 잡기 [세무민의 코딩일기] (1) | 2021.12.02 |
| 파이썬 웹 개발을 위한 기초 공부하기 1탄 - Flask 설치 및 오류 해결 [세무민의 코딩일기] (0) | 2021.11.28 |
| 세무민의 코딩일기 : 화재와 소방공무원 및 장비의 관계 분석(오랜만에 데이터 분석하기) (13) | 2021.07.17 |
| 세무민의 SVG 도전! [2] : 이미지에 색을 입혀보기! (0) | 2020.11.26 |